Guardrail Integration
DynamoGuard policies can be applied to various models in the Dynamo AI platform. DynamoGuard can be integrated into an LLM application using two methods: (1) Managed Inferenc Modee and (2) Analyze Mode.
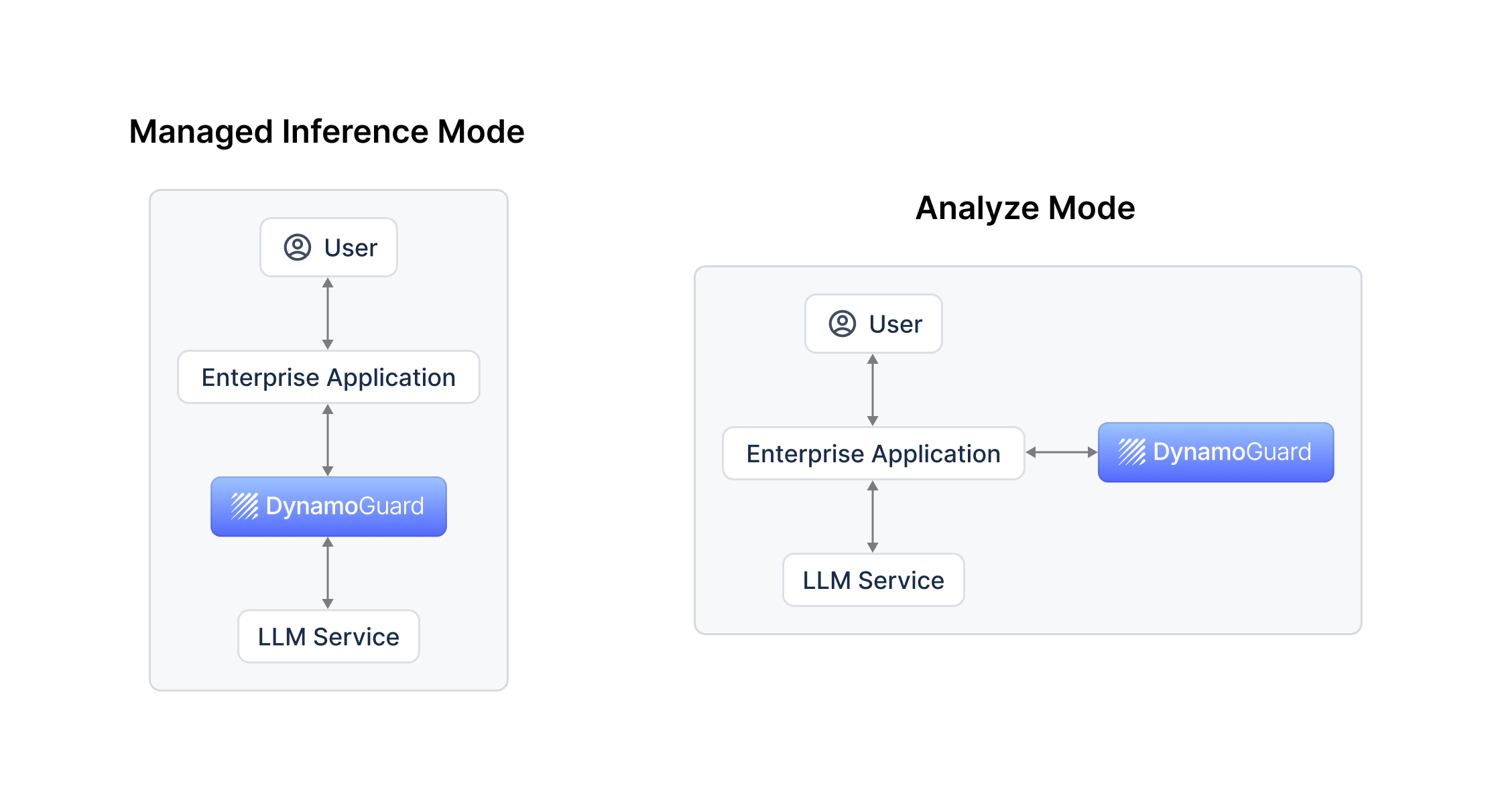
Managed Inference Mode
When using a model for DynamoGuard, a managed inference endpoint is automatically set up (/chat/). This endpoint should be used instead of the standard model endpoint in your application code and automatically handles the following workflow:
- DynamoGuard runs input policies on user input
- Based on policy results, user input is appropriately blocked, sanitized, or forwarded to the model
- If user input not blocked, request is sent to base model
- Model response is received by DynamoGuard
- DynamoGuard runs output policies on model response
- Based in policy results, model response is appropriately blocked, sanitized, or returned to the user
Remote Model Objects
Currently, Managed Inference Mode is only supported for Remote Model Objects. Remote Model Objects can be used to create a connection with any model that is provided by a third party or is already hosted and can be accessed through an API endpoint. Currently, DynamoFL supports the following providers, as well as custom endpoints: OpenAI, Azure OpenAI, Databricks, Mistral, AWS Bedrock
Analyze Mode
DynamoGuard can also be integrated into your application in a custom manner using the /analyze/ endpoint. The analyze endpoint provides a one-off analysis of a piece of text and returns the policy results. The analyze endpoint can be used as shown below.